MAERI 2.0 Tutorial @ ICS 2022
Overview
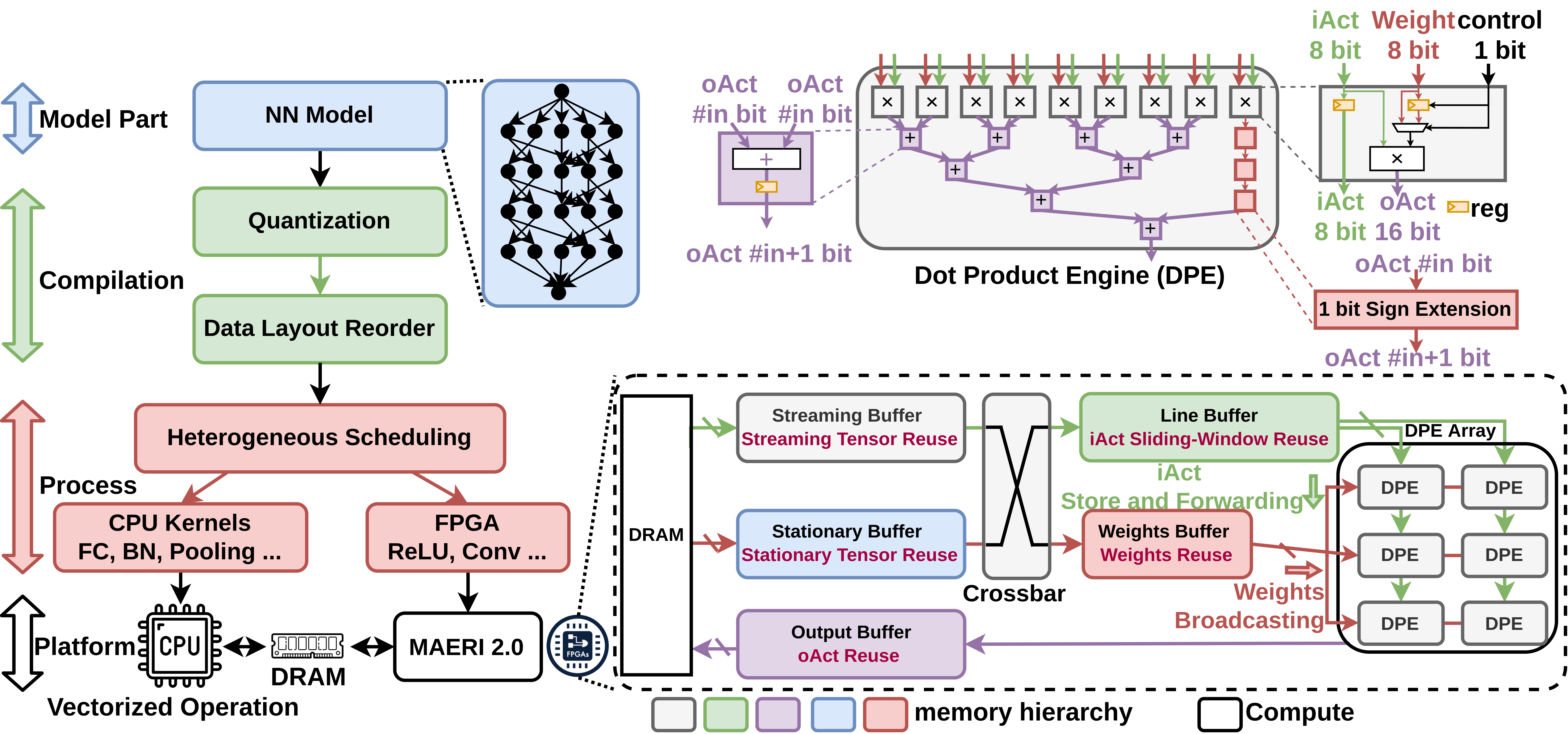
In this tutorial, we will educate the research community about the challenges in the emerging domain of Neural Network Accelerator, demonstrate the capabilities of MAERI 2.0 with examples and discuss ongoing development efforts.
Date
- Jun 27 th, 2022, 11:00 - 12:30 PM (CET) / 14:00 PM - 15:30 PM (ET)
- Virtual event.
Organizers
 |
Tushar Krishna (Georgia Tech) Website LinkedIn Tushar Krishna is an Associate Professor in the School of ECE at Georgia Tech since 2015. He also holds the ON Semiconductor Endowed Junior Professorship. He has a Ph.D. in Electrical Engineering and Computer Science from MIT (2014), a M.S.E in Electrical Engineering from Princeton University (2009), and a B.Tech in Electrical Engineering from the Indian Institute of Technology (IIT) Delhi (2007). Dr. Krishna’s research spans the computing stack: from circuits/physical design to microarchitecture to system software. His key focus area is in architecting the interconnection networks and communication protocols for efficient data movement within computer systems, both on-chip and in the cloud. |
 |
Jianming Tong (Georgia Tech) Website LinkedIn Jianming Tong is a Ph.D. student at Georgia Institute of Technology starting from Spring 2021, advised by Prof. Tushar Krishna. He received my bachelor degree at Xi'an Jiaotong University at 2020 supervised by Prof. Pengju Ren. He was a Research Assistant at Tsinghua Unversity working with Prof. Yu Wang. His research interests involve on-chip network, efficient high-perform domain-specific architecture design for neural network processing and homomorphic encryption acceleratrion. |
Description
Machine learning (ML) has become pervasive today. ML for science relies on leveraging Deep Neural Networks (DNNs)in scientific problems. This makes it crucial for HPC systems to run DNNs efficiently. To this end, modern HPCsystemsare increasingly deploying customized high-performance dataflow accelerators (e.g., Cerebras, Sambanova,) andFPGAsfor running next-generation DNNs. The focus of this tutorial is on demonstrating the design and deployment of a dataflowaccelerator called MAERI on FPGAs. Existing frameworks like Gemini, ESP and OpenCGRA all support end-to-end deployment of DNN modesl either throughsimulation or real FPGA. However, all of them assume a fixed underlying accelerator and could only explore mappingchoices on a fixed accelerator architecture. There is still a need for answering which hardware architecture tochooseand what parameters for the hardware is optimal for a given pattern of workloads.
As an ongoing project, we have been developing a framework, MAERI-FPGA, to deploy the software model onaflexible-template FPGA accelerator with parallelism, scheduling and hardware size as controllable knobs. Currently, MAERI-FPGA is deployed on Xilinx FPGAs (both embedded boards and PCI-E accelerator card) to support deeplearningmodel directly from Pytorch framework. To the best of our knowledge, MAERI-FPGA is the first open-sourceFPGAframework for exploring dataflow accelerator design space on real FPGA with end-to-end setup. In this tutorial, we will educate the research community about the impact of different design choices on the accelerators, demonstrate the capabilities of MAERI-FPGA with examples and discuss ongoing development efforts.
Target Audience:
The tutorial targets students, faculty, and researchers who want to
- understand how to design DNN accelerators, or
- study performance implications of dataflow mapping strategies, or
- prototype a DNN accelerator (on ASIC of FPGA)
Schedule
| Time (EDT) | Time (ET) | Agenda | Presenter | Resources |
|---|---|---|---|---|
| 14:00 | 14:30 | Introduction and Background of NN Accelerator | Tushar | Slide |
| Overview of Neural Network Inference Workload | ||||
| Dataflow and Mapping in Neural Network | ||||
| DNN Accelerator Flexibility | ||||
| 14:30 | 14:40 | break | ||
| 14:40 | 15:10 | MAERI 2.0: Flexible NN Accelerator Framework | Jianming | Slide |
| Supported Neural Network Model | ||||
| Quantization Flow | ||||
| Memory Layout | ||||
| Heterogeneous Scheduling | ||||
| MAERI 2.0 Microarchitecture | ||||
| 15:10 | 15:30 | Demo | Jianming | Slide |
| DEMO 1: Deploy MAERI 2.0 on Xilinx Embedded FPGA Board | ||||
| DEMO 2: Explore Performance Benefit of on-chip Buffer using MAERI 2.0 |
Resources
Installation
Repositories
To be released, send based on the request. Please email jianming.tong@gatech.edu if you need the source code. MAERI-verilog
Core Developers
- Jianming Tong (jianming.tong@gatech.edu, Georgia Tech)
- Yangyu Chen (yangyuchen@gatech.edu, Georgia Tech)
Additional Contributors
- Tushar Krishna (tushar@ece.gatech.edu, Georgia Tech)
- Abhimanyu Bambhaniya (abambhaniya3@gatech.edu, Georgia Tech)
- Taekyung Heo (taekyung@gatech.edu, Georgia Tech)
- Yue Pan (ypan331@gatech.edu, Georgia Tech)